
Корпоративные системы генерируют и обрабатывают колоссальные объёмы персональных данных. По данным InfoWatch, только в 2024 году из российских IT-систем утекло более 1,5 миллиарда записей ПД — рост на 30 % по сравнению с предыдущим годом. Почти треть от этого объёма составляет аутентификационная информация: пароли, логины, номера телефонов и адреса электронной почты.
Масштабы утечек поражают: за 2024 год зафиксировано 135 случаев утечки баз данных, содержащих более 710 миллионов записей о россиянах. Для сравнения — это почти в пять раз превышает численность населения страны. Помимо данных аутентификации утекают имена, даты рождения, паспортные данные, адреса, детали заказов и другая чувствительная информация. В материале — о технологии Named Entity Recognition (NER), которая позволяет находить в текстах чувствительные данные, чтобы скрыть их и не показать кому не надо.
Штрафы по 152-ФЗ
Нарушения в области персональных данных обходятся бизнесу всё дороже. С мая 2025 года в России действуют новые, кратно большие, штрафы за нарушения 152-ФЗ. За утечку персональных данных от 1000 до 10 000 субъектов организации грозит штраф от 3 до 5 миллионов рублей, а при повторных нарушениях — штрафы от 1 до 3 % выручки, но не менее 20 миллионов рублей.
Особенно ощутимые санкции предусмотрены за утечку специальных категорий персональных данных — штрафы для организаций могут достигать 15 миллионов рублей, а за утечку биометрических данных — до 20 миллионов. Помимо административной ответственности, с декабря 2024 года действует и уголовная статья 272.1 УК РФ, предусматривающая наказание до 6 лет лишения свободы за незаконные операции с персональными данными.
Утечки через языковые модели
Искусственный интеллект и языковые модели в бизнес-процессах создают дополнительные угрозы для конфиденциальности данных. Большие языковые модели (LLM) могут запоминать и непреднамеренно раскрывать персональную информацию, содержащуюся в обучающих данных или передаваемую пользователями.
Злоумышленники могут использовать модели для направленного извлечения частной информации из конфиденциальных наборов данных, генерируя множество запросов и анализируя выходные данные на предмет ключевых слов или паттернов.
Масштаб проблемы подтверждают исследования: например, стриминговый сервис Spotify не может устранить ряд утечек через LLM уже больше 5 лет.
Бум внедрения ИИ в бизнесе
Несмотря на риски, российские компании активно внедряют решения на базе искусственного интеллекта. По данным ИТ-холдинга Т1, к концу 2024 года 74 % компаний использовали ИИ в основной операционке — это на 12 % больше, чем в 2023-м. Инвестиции в искусственный интеллект в России выросли на 36 % и достигли 305 миллиардов рублей.
Генеративный ИИ применяют уже 20 % российских компаний, а рынок продуктов на основе LLM оценивают в 35 миллиардов рублей. Эксперты прогнозируют рост на 25 % ежегодно. Наибольшую востребованность получили цифровые ассистенты, которые внедряются в бухгалтерские и производственные процессы.
Как извлекать пользу из данных, не нарушая закон
Бизнес оказался в сложной ситуации: с одной стороны, персональные данные необходимы для качественной работы с клиентами, персонализации услуг и повышения эффективности. С другой — каждое нарушение требований к защите этих данных может обернуться серьёзными штрафами и репутационными потерями.
Компании ищут баланс между использованием современных ИИ-технологий и соблюдением требований законодательства о персональных данных. Один из инструментов защиты ПД — технологии распознавания именованных сущностей (Named Entity Recognition, NER). Они позволяют автоматически выявлять и маскировать персональную информацию до передачи данных в языковые модели или другие системы.
Технология NER Named Entity Recognition
Если в двух словах, то Named Entity Recognition (NER) — это умение машины читать текст примерно как человек: видеть в потоке слов не просто буквы, а конкретные сущности вроде имён, дат или названий компаний. В предложении «Вчера Анна Петрова встретилась с представителями Microsoft в Сколково» человек понимает, что Анна Петрова — это персона, Microsoft — организация, а Сколково — место. Этому можно научить и компьютеры.
Что такое Named Entity Recognition
Named Entity Recognition — это область обработки естественного языка (NLP, Natural Language Processing), которая занимается поиском и классификацией именованных сущностей в неструктурированном тексте. Проще говоря, это технология, которая помогает компьютеру понять, о чём или о ком идёт речь в тексте.
Основная задача NER в том, чтобы найти в тексте специфические объекты — те самые «именованные сущности» — и правильно их категоризировать. Это может быть всё что угодно — от имён людей до финансовых показателей.
Принципы работы
Работа NER строится на двух основных этапах:
- Распознавание сущностей. Система сканирует текст и выявляет фрагменты, которые потенциально могут быть именованными сущностями. Для этого происходит токенизация — разбиение текста на отдельные слова или токены, а затем извлечение признаков каждого токена: его морфологические особенности, синтаксическая роль в предложении, контекст.
- Классификация. Найденные сущности распределяются по категориям на основе их семантического значения и контекста. Последний особенно — например, слово «apple» в технологическом тексте означает компанию, а в кулинарном — фрукт.
Основные типы именованных сущностей
Классические системы NER обычно работают с базовым набором категорий:
PERSON (Персоны) — имена людей: «Анна Иванова», «Сергей Петрович»
ORGANIZATION (Организации) — названия компаний, учреждений: «Сбербанк», «МГУ»
LOCATION (Места) — географические объекты: «Москва», «Эбби Роуд»
DATE (Даты) — временные выражения: «вчера», «15 марта 2024 года»
MONEY (Деньги) — финансовые сущности: «1000 рублей», «$50»
PERCENT (Проценты) — процентные значения: «25%», «три четверти»
Современные специализированные системы могут работать с гораздо более узкими категориями в зависимости от предметной области.
Сферы применения NER
NER используют в самых разных областях бизнеса.
1. Финансы. Банки и страховые используют NER для обработки договоров, выделения ключевых условий, мониторинга финансовых новостей и соблюдения требований регуляторов. Например, система может автоматически извлекать суммы, даты платежей и названия контрагентов из тысяч документов.
2. Медицина. В медицинских картах NER помогает выделять названия заболеваний, лекарств, дозировки. Это помогает в анализе эффективности лечения и исследованиях. NER-системы анонимизируют медицинские данные прежде, чем передать их в исследовательские центры.
3. E-commerce. Интернет-магазины применяют NER для анализа отзывов покупателей — выделяют названия товаров, бренды, характеристики, о которых пишут пользователи. Это помогает лучше понимать потребности клиентов и работать над ассортиментом и сервисом.
4. СМИ и аналитика. Медиа-компании используют технологию для тегирования новостей, выделения ключевых персон и событий, создания аналитических сводок. Без этого не обойтись сейчас, когда инфополе перегружено огромными объёмами контента.
5. Поисковые системы. Google и другие поисковики применяют NER для лучшего понимания пользовательских запросов и релевантности результатов. Когда вы ищете «рестораны рядом с Большим театром», система понимает, что «Большой театр» — это конкретное место в Москве.
6. Чат-боты и голосовые ассистенты. Современные диалоговые системы используют NER для понимания пользовательских запросов. Когда пользователь говорит боту: «Забронируй столик в ресторане „Пушкин“ на завтра в 19:00», система должна выделить название ресторана, дату и время — именно за это отвечает NER.
Современные NER-системы экономят бизнесу время и деньги. Использование NER в автоматизации рутинных процессов может сократить время обработки документов на 60-80 %.
Эволюция технологических подходов к NER
Поговорим о том, как эта магия работает. За годы развития технологии инженеры испробовали множество подходов. Каждый имеет свои плюсы и минусы, и выбор подходящего метода во многом зависит от специфики задачи.
Rule-based системы
Это, по сути, попытка научить компьютер работать с текстом так, как это делали бы лингвисты до эпохи машинного обучения. Разработчики вручную создают правила и шаблоны на основе своих знаний о языке и предметной области.
Основные инструменты таких систем:
- Регулярные выражения — мощный инструмент для поиска паттернов в тексте. Например, можно создать выражение для поиска всех российских телефонных номеров. Выражение \+7\s?$$\d{3}$$\s?\d{3}-?\d{2}-?\d{2} найдёт номера вроде «+7 (495) 123-45-67». Такие правила работают быстро и предсказуемо, но требуют обновления при появлении новых форматов.
- Словари и справочники — заранее составленные списки известных сущностей. Банки часто используют справочники контрагентов, содержащие тысячи названий компаний. Когда система встречает в тексте договора «ООО Рога и копыта», она сразу распознаёт организацию благодаря словарю.
- Лингвистические правила — использование морфологических и синтаксических особенностей языка. Например, правило «слово с заглавной буквы в середине предложения, скорее всего, имя собственное» работает в большинстве случаев.
Преимущества rule-based систем — скорость работы, стопроцентная предсказуемость результатов, лёгкость в отладке и модификации правил. Такие системы идеально подходят для узких предметных областей с чёткими паттернами — например, для извлечения данных из типовых документов или обработки структурированных отчётов.
Недостатки — предельная негибкость, потребность вручную создавать правила для каждого нового случая, плохая адаптация к изменениям в данных. Если в вашей организации изменился формат документов, правила придётся переписывать.
Машинное обучение (CRF, SVM)
Следующим шагом стало применение алгоритмов машинного обучения, которые могут обучаться на размеченных данных и адаптироваться к новым паттернам без ручного программирования правил.
Conditional Random Fields (CRF) — это, пожалуй, самый успешный «классический» подход к NER. CRF учитывает не только отдельные слова, но и их взаимосвязи в последовательности. Если LSTM «читает» текст слева направо, то CRF анализирует всю последовательность целиком, что позволяет лучше понимать контекст.
CRF крут тем, что может моделировать зависимости между соседними элементами последовательности. Система понимает, что после слова «мистер» с высокой вероятностью должно идти фамилия человека, а после названия города — страна или регион.
По данным исследований, CRF-системы могут достигать точности 94-95% на задачах NER для английского языка — это довольно неплохо. Однако обучение таких моделей может занимать до 20 часов даже на относительно небольших датасетах.
Support Vector Machine (SVM) — классический алгоритм машинного обучения, который строит границу между классами в многомерном пространстве. Для задач NER SVM обычно работает на уровне отдельных слов, используя их характеристики: морфологию, позицию в предложении, окружающий контекст.
Этот подход требует серьёзной работы по инжинирингу признаков — извлечению информативных характеристик из текста. Разработчики вручную создают сотни признаков: «слово начинается с заглавной буквы», «предыдущее слово — предлог», «слово содержит цифры» и так далее.
Глубокое обучение — LSTM, BERT, трансформеры
Революция в NER началась с приходом глубокого обучения, которое автоматизировало процесс извлечения признаков и улучшило качество распознавания.
LSTM (Long Short-Term Memory) — рекуррентные нейронные сети, способные «помнить» длинные контексты. Двунаправленные LSTM (BiLSTM) читают текст сразу в обе стороны, что позволяет учитывать как предыдущий, так и последующий контекст каждого слова.
Архитектура BiLSTM-CRF стала золотым стандартом для NER на несколько лет. Она комбинирует способность LSTM понимать контекст с умением CRF моделировать зависимости между метками. Такие системы показывают точность 87-93 % на различных языках.
BERT и трансформеры — настоящий прорыв в обработке естественного языка. BERT использует механизм self-attention, который позволяет каждому слову «смотреть» на все остальные слова в предложении одновременно, а не только на соседние.
Ключевая особенность BERT — двунаправленная обработка контекста. В отличие от обычных языковых моделей, которые предсказывают следующее слово на основе предыдущих, BERT обучается предсказывать замаскированные слова, используя весь контекст предложения.
Для задач NER BERT показывает впечатляющие результаты: точность достигает 83-92 % для различных языков. Особенно хорошо BERT работает после дообучения на предметную область — например, на новостных или медицинских текстах.
Метрики разных подходов
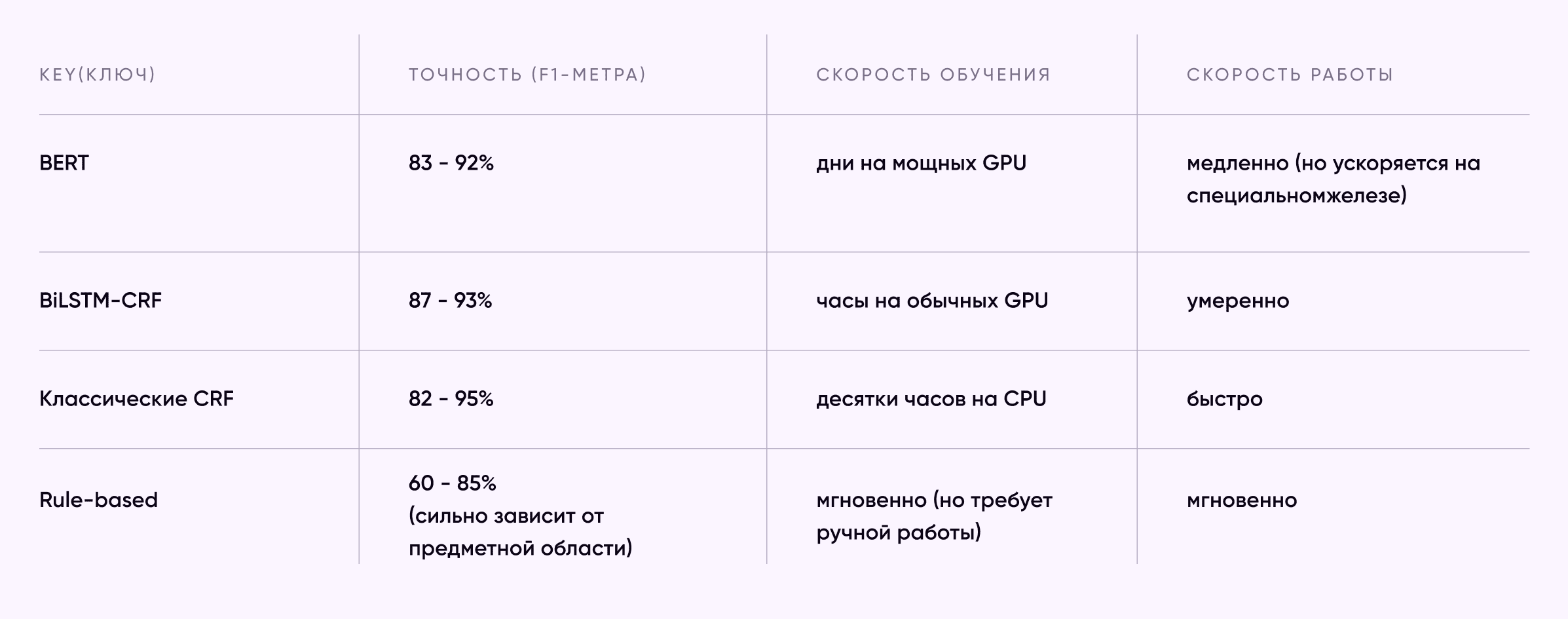
Интересно, что выбор подхода часто определяется не только точностью, но и практическими ограничениями. Если у вас есть мощные вычислительные ресурсы и большой размеченный датасет, BERT — оптимальный выбор. Для быстрых прототипов или ограниченных ресурсов всё ещё актуальны классические ML-подходы.
При этом гибриды нескольких методов показывают лучшие результаты, чем использование одного алгоритма. Например, можно сначала применить rule-based фильтрацию для очевидных случаев, а затем дообработать сложные примеры с помощью BERT.
Сложности и решения в русскоязычном NER
Работа с русским языком накладывает свои особенности и ограничения на технологии распознавания именованных сущностей. Несмотря на общий прогресс в NER, специфика русского языка требует от разработчиков нестандартных решений.
Особенности русского языка
- Сложная морфология и словоизменение. Русский язык богат падежами, окончаниями, склонениями и спряжениями. Одно имя или название может иметь десятки форм. Например, имя «Иван» может встречаться как «Ивана», «Ивану», «Иваном» и так далее. Значит, идентифицировать сущность по факту простого совпадения с словарём или шаблоном не всегда возможно.
- Ограниченность размеченных данных. Большинство качественных обучающих выборок — на английском языке. Для русского часто не хватает больших и разнообразных датасетов с точной разметкой сущностей. Эффективность обучения моделей на ограниченных наборах оставляет желать.
- Проблемы с регистром и пунктуацией. Имена часто пишут с ошибками в регистре — в чатах и соцсетях заглавных букв может не быть. Пунктуация в таких текстах и вовсе произвольная, и это осложняет сегментирование на логические части. Впрочем, это свойство неформального текста на любом языке.
Готовые решения
Открытые модели. Natasha — это набор инструментов с предобученными моделями для русского языка, включая NER, который умеет распознавать персоны, организации, локации и даже более специфические категории. DeepPavlov предлагает библиотеку с готовыми моделями и возможностью кастомизации под задачи заказчика. При этом у этих решений есть свои недостатки: DeepPavlov много весит, а сравнительно старая Natasha зависима от грамматики и работает только с русскими именами.
Облачные сервисы. Крупные российские IT-компании предлагают облачные API для распознавания сущностей в текстах. Например, Yandex.Cloud предоставляет NER-сервисы с поддержкой русского языка, интегрированные с другими инструментами обработки данных. VK Cloud также развивает платформу с возможностями анализа текстов для бизнеса.
Несмотря на высокий уровень развития, даже лучшие модели на русском языке иногда сталкиваются с ошибками: путаницей в определении границ сущностей, проблемами с редкими именами и жаргоном, а также снижением точности на сленговых или диалектных текстах.
В одном из следующих материалов — о том, как мы отказались от всех готовых решений и дообучили свою модель распознавать в текстах ФИО на разных языках.
Подпишитесь на наш телеграм-канал