
На бизнес-конференциях и в блогах рассказывают о том, как круты современные боты поддержки — всё понимают, разгружают людей, сокращают сроки решения проблем и расходы компании... На больших цифрах это так. Но у каждого есть кулстори о том, что «тупые боты ничего не умеют», бесят и в лучшем случае способны перевести тебя на живого оператора (но не всегда). И сегодня можно позвонить, например, в медицинский центр и столкнуться вот с таким:
— Здравствуйте. Это робот поддержки «Надежда». Вы позвонили в медицинский центр «X». У нас есть приложение, где вы можете записаться на приём. Отправить вам ссылку на установку приложения?
— Нет, мне нужно поговорить с человеком.
— Спасибо, что обратились к нам. До свидания!

Однако есть боты, которые действительно впечатляют. Клиент задаёт вопрос службе поддержки и мгновенно получает исчерпывающий точный ответ. Сотрудник обращается за конкретной информацией, скрытой где-то среди сотен корпоративных документов — и получает её за пару секунд, без регистрации и смс. И заметьте: ни один сотрудник поддержки или HR не пострадал.
Такие возможности даёт технология RAG, построенная на графах знаний. Расскажем, как это работает.
Эволюция чат-ботов
→ Сценарные боты
Первые чат-боты, которые стал широко использовать бизнес, работали по жёстким сценариям. Они так и назывались — «сценарные». Если пользователь вводил ключевое слово, бот улавливал именно его и выдавал заранее написанный ответ. Например, на запрос, где есть слова «возврат» или «вернуть» — стандартную инструкцию по возврату товара.
Такие системы часто бесили пользователей. Вопрос пользователя может содержать слово «возврат», но это вовсе не значит, что пользователю нужна вся стандартная инструкция по возврату. Даже напротив: скорее всего, вопрос связан с нестандартной ситуацией, и предлагать пользователю обычный гайд — верный способ разозлить его.
Кроме того, обновить базу ответов было сложно — иногда требовалось переписывать сотни сценариев.
→ Retrieval Augmented Generation 1.0. Векторы
Ситуация изменилась с появлением технологии RAG, Retrieval Augmented Generation. Эта технология позволяет нейросетям искать информацию в документах компании и генерировать ответы на лету. Например, на вопрос «Как оформить возврат товара, купленного со скидкой?» система анализирует политику возвратов, условия скидочных акций и выдает персонализированный ответ.
Такие чат-боты работали (и продолжают работать) с корпоративными знаниями, упакованными в векторные базы данных.
Как работает RAG на основе векторов
Представим, что нам нужно создать RAG на основе какого-то документа для компании «Ромашка». Упрощённо это выглядит так:
1. Разделяем документ на чанки (фрагмент текста) и векторизируем их (переводим текст в числа).
2. Загружаем это всё в базу данных в формате:

3. Подбираем языковую модель, которая будет отвечать на пользовательские вопросы, используя контекст, добытый из базы знаний.
Теперь посмотрим, как такая система будет работать с запросом пользователя.
1. Пользователь спрашивает: «Как мне устроиться на работу в компанию „Ромашка“?»
2. Вопрос пользователя векторизируется.
3. Система ищет наиболее релевантные запросу чанки:
- Извлекает ключи из нашей базы данных.
- Вычисляет косинусную схожесть между каждым ключом и вопросом пользователя. Получает score — метрику схожести.
- Выбирает ключи с наибольшим показателем score.
- Для выбранных ключей извлекает соответствующие чанки.
4. Передаёт в LLM (языковую модель) вопрос пользователя и релевантные чанки, найденные в базе.
5. Модель генерирует ответ, система отдаёт его пользователю.
Сегодня ботов на базе Retrieval Augmented Generation используют многие компании — от банков до e-commerce. Однако у классической версии этой технологии есть нюансы.
Ограничения векторного RAG
Даже продвинутый относительно сценарных ботов RAG — не безупречен. Вот с какими проблемами сталкиваются компании:
Поиск и компоновка разрозненных данных. Мы уже говорили, что в рамках подготовки базы знаний к «RAGификации» документы в ней делятся на чанки — фрагменты текста. Деление на чанки часто происходит без учёта содержимого, и смысловой связи между чанками нет. Если текст описывает логику какого-то процесса (то есть почти всегда) — она оказывается разбросанной по нескольким чанкам. И даже если бот верно понял вопрос пользователя, то собрать кусочки релевантной информации по разным чанкам и «склеить» их в корректный полный ответ он уже не может. Результат — излишне общий или вовсе ошибочный ответ.
Сложности с обновлением данных. Добавляя в базу новые данные, нужно удалить неактуальные. А найти чанки с этой устаревшей информацией не так просто, поскольку они, как мы помним, разбросаны и не связаны между собой логически. Удаление одного чанка не затрагивает другие, даже если они относятся к той же теме. В конце ещё нужно сделать переиндексацию базы.
Retrieval Augmented Generation 2.0. Графы знаний
Напомним: векторное представление информации подразумевает, что тексты разбивают на фрагменты (чанки), которые затем преобразуют в числовые векторы (математические представления). В ответ на запрос пользователя система ищет чанки, векторы которых ближе всего к вектору вопроса — и делает это через метрики вроде косинусной схожести.
Чанки анализируются изолированно. Как следствие, бот часто не видит широкого контекста и хуже справляется с обработкой сложных запросов, где важны связи между темами.
Решить эти проблемы помогает организация базы знаний в виде графов. Граф позволяет представить информацию в виде структуры из двух видов сущностей:
- Узлы. Это темы в системе знаний. На примере ритейла темами могут быть те же «возврат товара» и «кредитные программы».
- Связи. Это отношения между темами. Связь между упомянутыми темами может выглядеть так: «возврат товара → зависит от → условий кредита»
Граф схож с молекулой, в которой атомы связаны друг с другом:
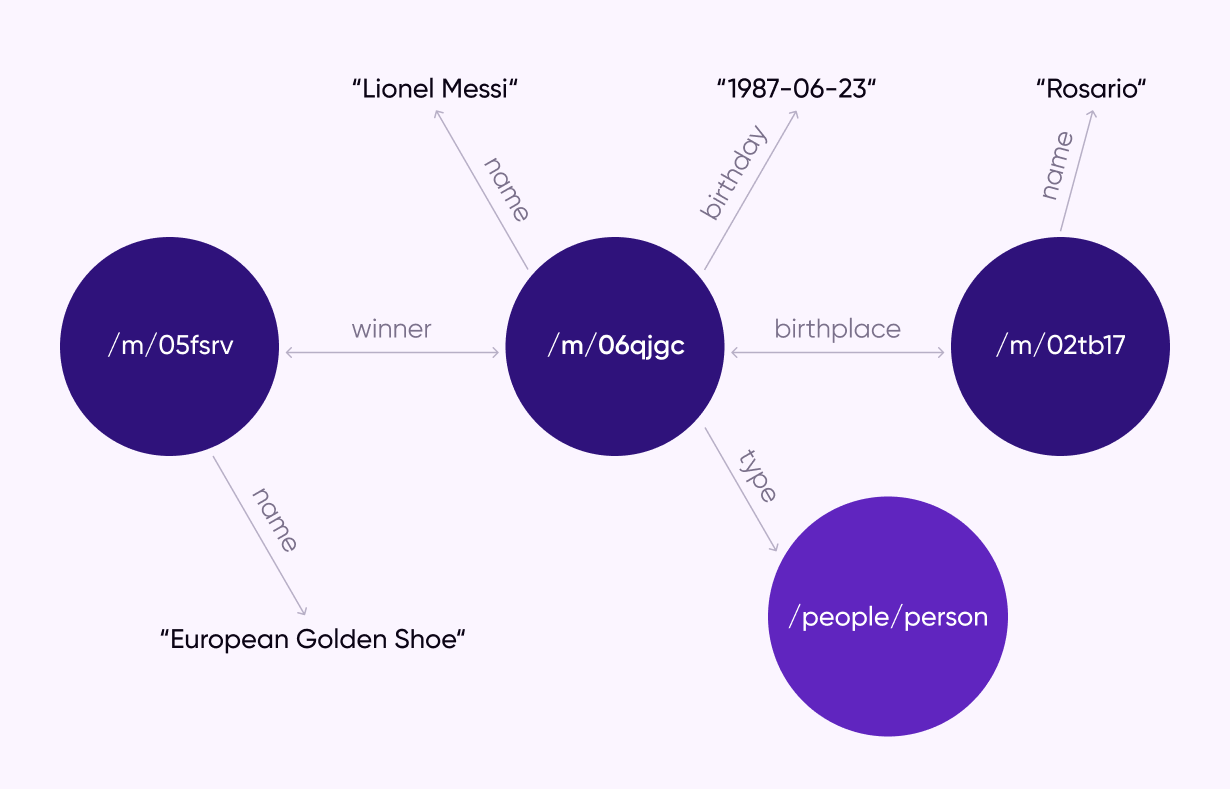
На вопрос клиента «Могу ли я вернуть товар, купленный в рассрочку?» система на основе графового RAG ищет в графе узлы, связанные с «возвратом» и «рассрочкой». Нейросеть анализирует связи между ними и генерирует ответ на основе конкретных правил, освещающих кейс возврата товара, приобретённого в рассрочку.
Вспомним, какие «болячки» свойственны традиционной векторной RAG-системе: непонимание контекста и додумывание (aka галлюцинации). Вот как Graph RAG работает с ними:
- Точность. Система понимает контекст, видит большую картинку вашего запроса, а не просто ищет ключевые слова.
- Минимум галлюцинаций. Система на основе графовой RAG меньше склонна галлюцинировать, так как лучше понимает, что вы ищете.
Как работает RAG-бот на основе графов знаний
1. Делим всю информацию в документах на смысловые блоки. Вместо деления текста на случайные или семантические чанки, не связанные между собой, ИИ выделяет темы, единицы смысла. Это те же чанки, но не нарезанные рандомно, а посвящённые тому или иному вопросу. Если смысловые чанки слишком большие — их можно разделить на подтемы.
Вот как это выглядит:
{ «Возврат товара»: { «Условия»: «Товар должен быть в оригинальной упаковке...», «Исключения»: «Не подлежат возврату электроника и...», «Сроки»: «До 14 дней с момента покупки» }}
2. Выстраиваем связи между смысловыми блоками. Алгоритм автоматически определяет, как темы связаны между собой, выстраивает между ними «родственные отношения». Вот примеры связей:
- «Рассрочка» → влияет на → «Возврат товара».
- «Акции» → исключает → «Возврат товаров со скидкой».
3. Ищем информацию и генерируем ответ. Когда от пользователя поступает запрос, система выполняет следующие шаги:
- Оценивает схожесть вопроса с узлами графа. Для этого используется так называемый score — числовой показатель, отражающий «степень совпадения» запроса с данными в узлах. Значение score может быть от 0 до 1, где 1 — полное совпадение.
- Выбирает узлы, чей score свидетельствует о высокой релевантности запросу пользователя. Определить эту релевантность помогает показатель threshold. Это такой «фильтр», который отсекает слабо связанную с запросом информацию.
- Передаёт данные с высоким показателем threshold в языковую модель, которая генерирует ответ.
К слову, обновление графа знаний проще, чем векторной базы. Вот как это работает:
1. Добавление данных
- Новый документ (например, обновленная политика возвратов) автоматически разбивается на темы.
- Система создаёт узлы («Новые сроки возврата») и привязывает их к уже существующим («Возврат товара», «Условия акций»).
2. Корректировка связей
Если в документах меняются правила (например, «возврат электроники теперь возможен»), алгоритм перестраивает связи:
- Старая связь: «Электроника → не подлежит возврату».
- Новая связь: «Электроника → возвращается при условии → сохранения упаковки».
3. Автоматизация
Современные инструменты сами находят места для интеграции новых данных. Например, при добавлении раздела «Криптовалютные платежи», система свяжет его с узлами «Оплата» и «Безопасность».
Не нужно пересчитывать векторы для всех документов — изменения затрагивают только связанные узлы. Конфликты данных видны сразу: если новый узел противоречит старому, система это подсветит.
Векторы и графы — не конкуренты
На практике ни одно решение не идеально: векторные методы отлично работают с семантикой, а графы — с контекстом и связями. Поэтому современные системы часто комбинируют оба подхода. Вместе они лучше выполняют задачу пользователя.
Скорость + глубина
- Векторы мгновенно находят фрагменты текста, близкие по смыслу к запросу.
- Графы добавляют контекст: показывают, как фрагменты связаны между собой.
Например, по уже знакомому нам запросу «Как оформить возврат товара, купленного в кредит?» векторный поиск находит чанки «возврат товара», «кредитные условия» и «документы для возврата». Граф знаний связывает их в логическую цепочку:
«Возврат товара» → требует → «Закрытие кредита» → зависит от → «Подтверждающих документов». В результате нейросеть генерирует ответ, который учитывает не только отдельные фрагменты, но и правила их взаимодействия.
Разные типы запросов
- Векторы эффективны для общих вопросов, как «Что такое возврат товара?».
- Графы незаменимы для сложных запросов с условиями — «Как вернуть товар, если я оформил рассрочку и потерял чек?».
Экономия ресурсов
- Первичный поиск через векторы сокращает количество данных для анализа.
- После этого графы работают только с релевантными узлами, что снижает нагрузку на систему.
Векторы и графы — не конкуренты, а союзники. Их комбинация позволяет поддерживать скорость работы, устранить «слепые зоны» в данных и обрабатывать запросы разного уровня сложности.
TL;DR
- Графы знаний vs. хаос.
Графы организуют информацию в узлы (темы) и связи (отношения), превращая разрозненные документы в логичную сеть. Это позволяет ботам понимать контекст запросов, а не просто искать ключевые слова. - Точность вместо галлюцинаций
Благодаря связям между темами, ИИ меньше «додумывает» ответы. Например, запрос о возврате товара в кредит находит не отдельные фрагменты, а цепочку правил. - Простое обновление
Добавить новый документ в граф — как проложить новую дорогу на карте: система сама свяжет его с существующими узлами. Не нужно перестраивать всю базу. - Векторы + графы = ♥️
Векторы быстро находят релевантные фрагменты, графы добавляют контекст. Вместе они обрабатывают и простые, и сложные запросы, экономя ресурсы системы. - Графы знаний делают чат-ботов не просто «читалками документов», а умными помощниками, которые видят связи между данными. Это следующий шаг к ИИ, который действительно понимает ваш бизнес
Подпишитесь на наш телеграм-канал