
В наших материалах мы уже упоминали, что большие языковые модели (LLM) обучаются на «человеческом» материале — огромном массиве текстов разной тематики, созданных разными людьми. Поглощая эти тексты, модель вычленяет закономерности, связи, суждения и учится генерировать свои ответы.
Таким образом ответы, что мы получаем от ИИ-агента — квинтэссенция всего человеческого, и если нам что-то не нравится, претензии разумно предъявлять не роботу, а самим людям. Излишне формальный тон сообщений, насмешка или дискриминационное высказывание в сообщениях агента — это зеркальное отражение того, как думает, говорит и поступает человек.
К тому же мы ожидаем, что робот лучше (умнее, тактичнее, порядочнее, etc.) человека. А он тоже ошибается — не считывает контекст, не понимает иронию или выбирает неуместный тон коммуникаций. Человек с этими вызовами, как правило, справляется лучше.
Как пофиксить эти недостатки ИИ-агентов? Интуитивно кажется, что нужно объединить потенциал ИИ и человека — и научить робота соответствовать высокой планке, которую мы ему ставим. Так и появилась технология Reinforcement learning from human feedback (RLHF) — Обучение с подкреплением на основе отзывов людей. О ней в этой статье.
Вначале давайте разберём термин. В словосочетании Reinforcement learning from human feedback, кажется, ясна вторая часть — human feedback. В наиболее распространённой версии в русскоязычном варианте это звучит как «отзывы людей». Возможно, корректнее было бы «обратная связь от человека», но это нюансы.
А что за reinforcement learning?
Что за Reinforcement Learning?
Reinforcement Learning (RL) — это обучение с подкреплением, метод машинного обучения, при котором агент учится принимать решения через взаимодействие с окружающей средой. Процесс обучения с подкреплением требует наличия нескольких компонентов:
1. Agent (Агент). Система, которая принимает решения и выполняет действия.
2. Environment (Среда). Всё, с чем взаимодействует агент. Она предоставляет агенту информацию о текущем состоянии и наградах.
3. Reward (Награда/Штраф). Сигнал, получаемый агентом от среды, который указывает на успех или неуспех его действия.
4. Policy (Стратегия, часто называемая Политикой). Стратегия, в соответствии с которой агент предпринимает те или иные действия в различных состояниях.
В отличие от классического метода обучения с учителем (supervised learning) в процессе RL отсутствуют предварительно размеченные данные — то есть агент не получает информации о среде, с которой ему нужно взаимодействовать.
Обучение модели происходит так же, как обучение человека или любого другого животного — на основе метода проб и ошибок. В ответ на свои действия агент получает сигналы подкрепления — награды или штрафы. Цель агента в том, чтобы получить максимальную награду за определённый период времени. На основе сигналов агент строит стратегию взаимодействия с конкретной средой.
Таким образом, цель Reinforcement Learning — сформировать оптимальный алгоритм (стратегию) взаимодействия со средой для достижения желаемого результата.
Откуда агент получает сигналы?
В процессе классического обучения с подкреплением агент получает награды (rewards) от окружающей среды, с которой он взаимодействует. Награды могут быть как положительными, так и отрицательными. Они служат сигналами для оценки успешности действий агента.
Агент получает вознаграждение за выполнение желаемого действия или достижение определённой цели. Например, в игре агент может получать очки за победу над противником или за выполнение уровня. А за нежелательные действия, такие как столкновение с препятствием или проигрыш в игре агент получит штраф.
Награды могут поступать непосредственно от среды, в которой работает агент. Например, в робототехнике агент может получать награды за успешное выполнение задач по перемещению объектов или навигации по маршруту.
Задачи для обучения с подкреплением
Метод обучения с подкреплением широко используется в машинном обучении и показывает классные результаты во многих сферах. Агенты, обученные на RL, хорошо справляются не только с задачами, в которых определить успешный исход сравнительно несложно, но и там, где определение «правильности» и успеха не столь очевидно.
- Автономное вождение
При управлении автономным автомобилем часто нет однозначно правильных или неправильных действий. Агенту нужно балансировать между безопасностью, эффективностью, комфортом пассажиров и другими факторами. Обучение с подкреплением позволяет ему учиться на опыте вождения в реальных условиях и вырабатывать оптимальные стратегии поведения на дороге.
- Торговые стратегии на финансовых рынках
При торговле ценными бумагами или другими активами нет гарантии, что конкретное решение будет правильным. Успех зависит от множества факторов, которые сложно предсказать. Агент, обученный с помощью RL, может анализировать большие объёмы данных, выявлять скрытые закономерности и адаптировать свои торговые стратегии к меняющимся рыночным условиям.
- Стратегии поведения в играх
В играх, особенно многопользовательских, часто нет однозначно верных решений. Успех зависит от действий других игроков, непредсказуемых событий и общей стратегии. RL позволяет агентам обучаться на опыте реальной игры и вырабатывать оптимальные стратегии поведения в различных игровых ситуациях.
- Управление ресурсами в ритейле
Управляя запасами в розничной торговле, нужно учитывать множество факторов — спрос, сезонность, акции поставщиков... Решение, правильное в одном случае, может оказаться неверным в другом. Агент, обученный с помощью RL, может адаптировать свои стратегии управления запасами к конкретным условиям каждого магазина и максимизировать прибыль.
Таким образом, обучение с подкреплением особенно эффективно в задачах, где правильность решения зависит от множества факторов и нет однозначных ответов. Оно позволяет агентам учиться на опыте и вырабатывать оптимальные стратегии поведения в сложных, динамических средах.
Привлекаем человека
Каждый, кто работает с ChatGPT или любыми другими ИИ-агентами, хотя бы раз ловил себя на ощущении, будто тот отвечает не вопрос в целом, а лишь ухватив два-три ключевых слова. А ещё бывает, что ИИ-помощник отпускает реплики, которые звучат не слишком корректно и дружелюбно, или даёт советы, которые не отвечают общечеловеческим гуманистическим ценностям. С агентами новых поколений такое случается реже и всё же...


Ещё ИИ-агенты пока не так круто справляются с нюансами, тонкостями, пониманием широкого контекста запроса, коннотациями и двойными смыслами. И любят давать ответы с «водянистыми», бесполезными формулировками.
Здесь вступает в игру человек. При всех своих ограничениях с этими вызовами он работает лучше. Идея витала в воздухе — почему бы не привлечь человека к (до)обучению LLM? Так технология RL получила новую разновидность — Reinforcement learning from human feedback.
Суть RLHF в том, что человек (его называют аннотатор) оценивает ответы агента, помечая их как ок или не ок. На основе этого фидбека агент дообучается. Каждый круг отзывов от человека оптимизирует модель и её стратегию — и повышает шансы дать релевантный ответ, который понравится реальному живому пользователю.
Этапы RLHF
Вот как может выглядеть флоу RLHF:
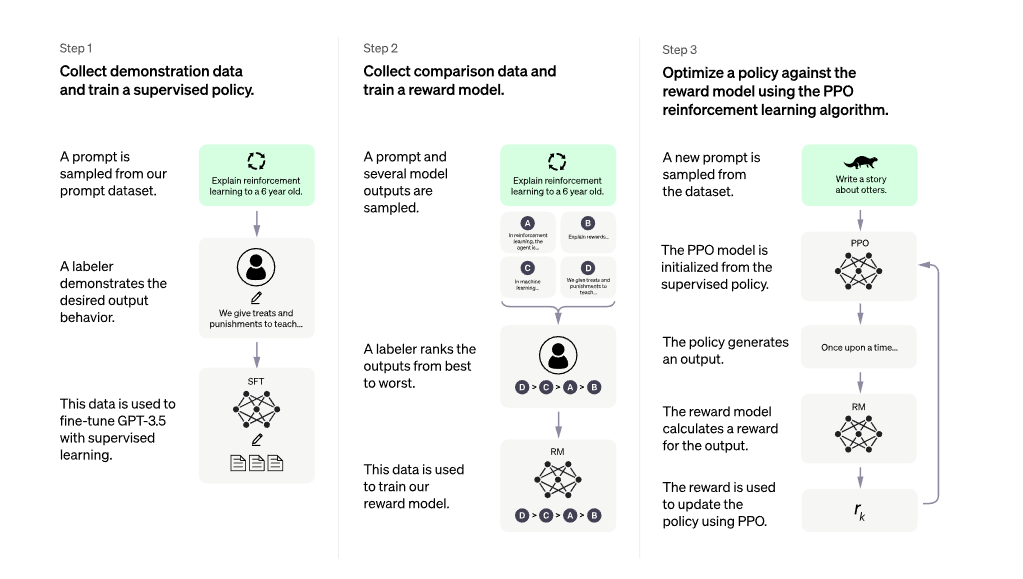
1. Подготовка обучающих данных. Люди готовят промпты (запросы) и идеальные ответы на них.
2. Предварительное обучение основной языковой модели с учителем (supervised learning). Можно не проводить самостоятельное обучение с нуля, а взять готовую предобученную коммерческую модель.
3. Основная модель генерирует ответы на запросы из пункта 1. Аннотатор сравнивает ответы модели с идеальными ответами, подготовленными человеком, и ранжирует их по качеству, полезности и соответствию ожиданиям.
Благодаря этому фидбеку от людей модель корректирует стратегию (политику) формирования ответов так, чтобы они были ближе к ответам людей. Но возлагать на людей весь процесс дообучения было бы слишком дорого и трудоёмко. Поэтому… 👇
4. На основе стратегии обучают модель вознаграждения. В разных источниках её называют reward model или preference model. Эта предварительно обученная модель, которая дообучается на основе фидбека от человека, чтобы в дальнейшем ориентироваться на требования человека, быть его «представителем».
5. Модель вознаграждения «представляет» человека в обучении основной модели, оценивая её ответы как будто с «человеческой» точки зрения. Шаги 3-5 повторяются несколько раз.
Теперь, выбирая ответ на каждый запрос, основная модель будет ориентироваться на стандарты, задаваемые моделью вознаграждения, стараясь найти тот, что с большей вероятностью понравится модели вознаграждения, а значит, и человеку. Так происходит оптимизация основной модели и улучшение качества её ответов.
Области применения
Как мы уже упомянули, RLHF эффективно применяется для решения задач, где ожидаемое успешное действие сформулировать не так просто:
→ Обработка естественного языка (Natural Language Understanding + Natural Language Processing)
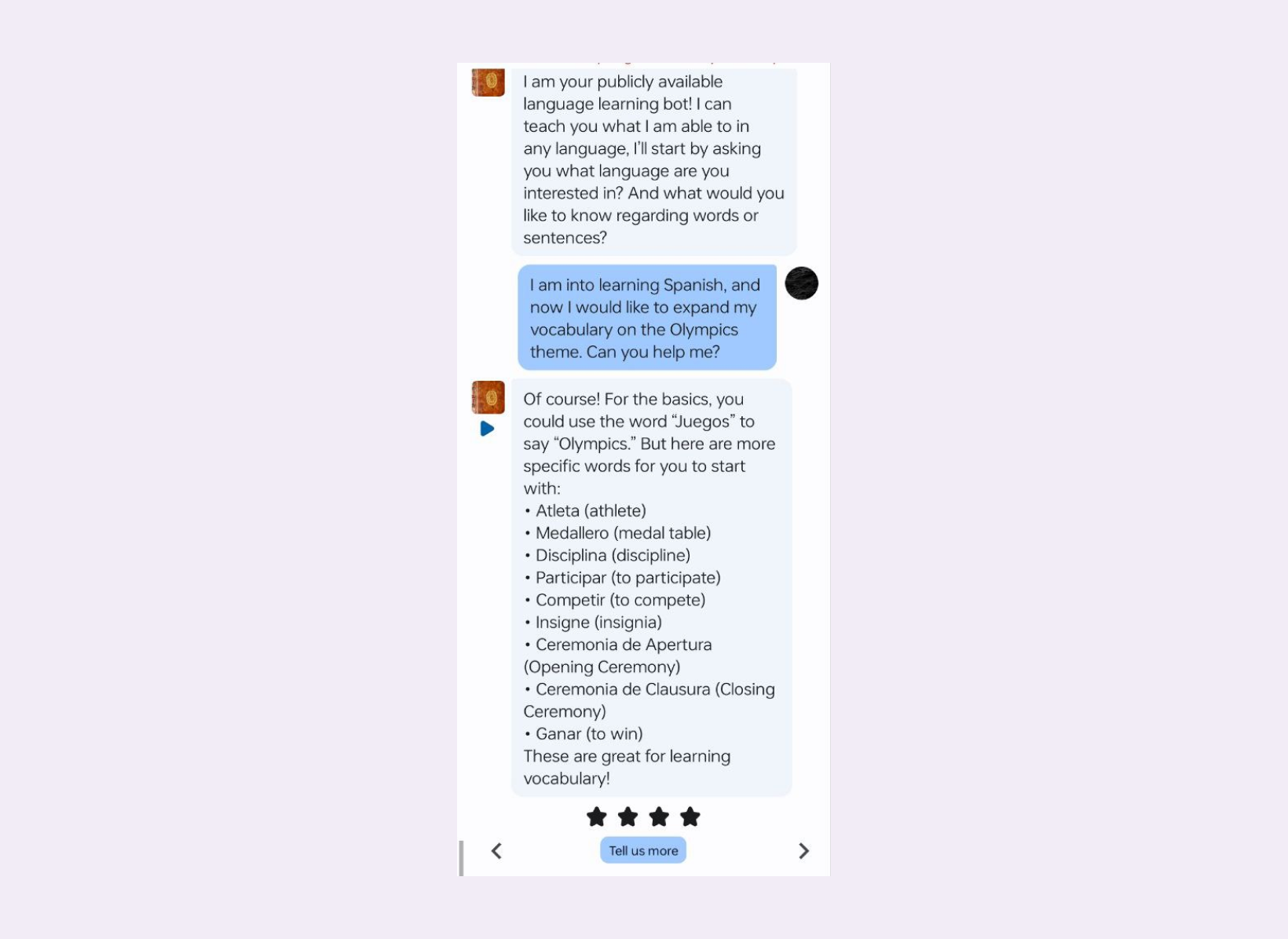
Обучение с подкреплением от человека помогает улучшать работу разговорных агентов (conversational agents). Пример — популярный сервис character.ai, где пользователю предлагают оценить сообщение от агента и при необходимости дать комментарий.
Технология помогает агентам делать более качественные саммари текста, а также более чутко реагировать на эмоциональную составляющую диалога и точнее подбирать тональность ответов.
С помощью RLHF агенты учатся подавать информацию в более полезном виде. Например, рассказывая о погоде, можно просто насыпать числовых показателей — температуру, влажность, атмосферное давление... А можно рассказать о том, как человек будет ощущать такие метеоусловия, как лучше одеться и вести себя за рулём в такую погоду.
Ещё одна задача, где человек помогает ИИ — переводы. Качество переводов агента, который учился при помощи фидбека от аннотаторов, заметно выше.
Успешные сегодня агенты Chat GPT и Sparrow проходили и продолжают проходить обучение с помощью RLHF. Это стало известно в том числе благодаря скандальной новости о том, что Open AI использовала для дообучения Chat GPT сотрудников из Кении, которые получали меньше $2 в час.

→ Компьютерное зрение
RLHF, используемый в моделях преобразования текста в изображение, помогает улучшить качество сгенерированных изображений, подтягивая их уровень до ожиданий пользователя.
→ Разработка игр
RLHF применяют для обучения игровых ботов — их работу оценивают и оптимизируют на основе оценок людей, а не традиционных показателей в баллах.
Проблемы и ограничения
Несмотря на преимущества, RLHF сталкивается с проблемами:
- Сбор данных. Сбор качественной человеческой обратной связи от людей может быть дорогим и трудоёмким. При этом качество фидбека — ключевой фактор в этом методе обучения.
К тому же негативную роль может сыграть предвзятость в обратной связи — например, если выборка аннотаторов недостаточно разнообразана по демографическим и другим характеристикам. И в целом нужно учитывать, что мнение человека субъективно, а значит, в каких-то случаях ответы агента, обученного на фидбеке от человека, будут неоднозначно восприняты разными пользователем. - Переобучение (overfitting). Агент может запоминать конкретный эпизод фидбека и не делать на его основе нужных обобщений. Тогда с будущем он прекрасно отработает абсолютно аналогичный контекст, но не справится с похожими случаями, которые, казалось бы, встраиваются в тот же паттерн.
- Риски манипуляции. Модели могут использовать систему обратной связи, обучаясь производить результаты, которые привлекательны внешне, а не действительно эффективны. Например, давать чрезмерно вежливые, но неинформативные ответы, уклоняться от сложных вопросов, прикрываясь общими фразами, соглашаться с пользователем без всяких на то оснований или давать общие советы, которые звучат полезно, но не имеют конкретного применения.

Подпишитесь на наш телеграм-канал